Garbage Collector – Ce que c’est et pourquoi tout développeur devrait le comprendre
La plupart des développeurs ont déjà été confrontés à une situation dans laquelle une application commence à se comporter de manière étrange sans cause évidente. L’utilisation de la mémoire augmente progressivement, les temps de réponse se dégradent, et quelqu’un finit par proposer de redémarrer le service. Souvent, cela fonctionne — au moins temporairement. Le problème, cependant, est rarement résolu. Il disparaît simplement du champ de vision, pour réapparaître plus tard, peut-être sous une autre forme, peut-être lorsque la charge augmente.
Étonnamment souvent, l’attention se porte alors sur les mauvais éléments. On cherche des défauts dans les algorithmes, les bases de données ou la couche réseau, alors que le facteur explicatif réel est bien plus fondamental. Le cœur du problème est que le développeur ne comprend pas pleinement ce que le runtime du langage fait en son nom. L’un des composants les plus critiques, et pourtant les moins bien compris, de ce runtime est le garbage collector.
Le garbage collector n’est ni un détail d’implémentation mineur ni une fonctionnalité périphérique. Dans de nombreux langages, il constitue une partie centrale du modèle d’exécution. S’il n’est pas compris, le comportement réel d’une application en production ne peut pas être compris non plus.
Ce qu’est réellement un garbage collector
On décrit souvent la collecte des déchets comme s’il s’agissait d’un nettoyeur en arrière-plan qui libère occasionnellement de la mémoire inutilisée. La métaphore est séduisante, mais trompeuse. Un garbage collector n’est ni un assistant invisible ni une simple commodité sans coût. C’est un système actif du runtime qui prend des décisions au nom du programme.
Concrètement, le garbage collector décide du moment où la mémoire est libérée. Il ne demande pas l’autorisation du développeur et ne suit pas les intentions implicites exprimées dans le code. Il fonctionne selon son propre modèle et ses heuristiques. En utilisant un langage à garbage collection, le développeur renonce volontairement au contrôle précis du moment de la libération de la mémoire. En échange, il obtient davantage de sécurité, une vitesse de développement accrue et l’élimination de toute une catégorie d’erreurs liées à la gestion de la mémoire.
Il ne s’agit ni d’un défaut ni d’une faiblesse. C’est un compromis assumé. L’essentiel est de comprendre que la responsabilité ne disparaît pas ; elle se déplace simplement du développeur vers le système d’exécution.
Pourquoi la garbage collection a été inventée
Sans garbage collector, le développeur est responsable de chaque allocation et de chaque libération de mémoire. Ce modèle est efficace et prévisible, mais cognitivement exigeant. Une seule erreur peut entraîner des fuites mémoire, des libérations multiples ou des références vers une mémoire déjà libérée. Ces erreurs ne se manifestent que rarement immédiatement ; elles apparaissent souvent sous charge en production, parfois de manière non déterministe.
La garbage collection a été introduite précisément pour résoudre ces problèmes. Son objectif était de rendre possibles des systèmes logiciels vastes, durables et complexes sans exiger de chaque développeur une maîtrise complète de la gestion mémoire de bas niveau. Parallèlement, les langages de programmation pouvaient offrir des garanties de sécurité plus fortes.
Le coût de cette approche est clair. Une fois que le moment de la libération de la mémoire est délégué au runtime, le comportement du programme n’est plus entièrement déterministe. Le développeur ne peut plus indiquer avec précision quand la mémoire sera libérée. Il ne peut qu’influencer ce moment de manière indirecte.
Comment le garbage collector « voit » votre code
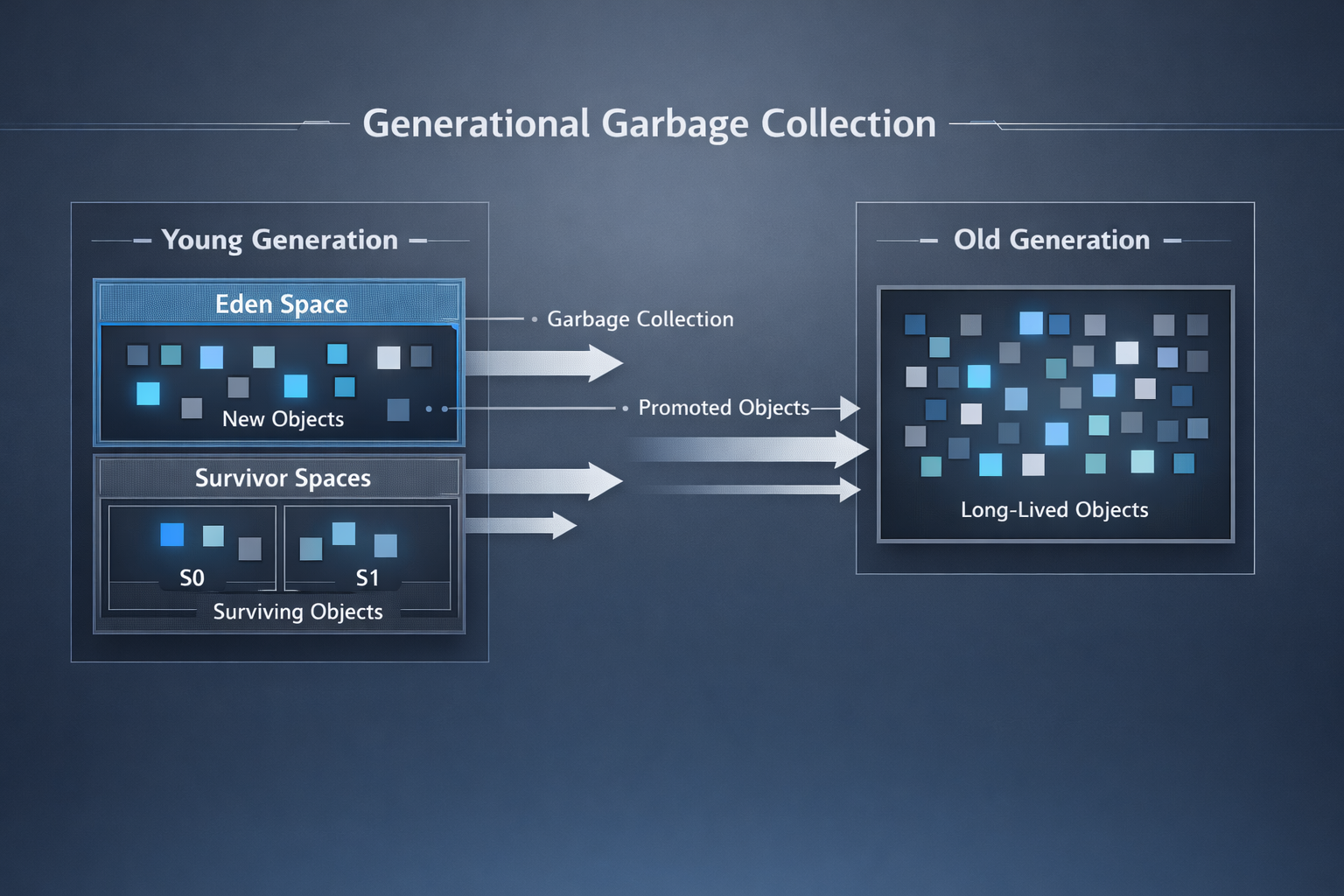
À ce stade, il est important de comprendre qu’un garbage collector ne traite généralement pas toute la mémoire de la même manière. La plupart des collecteurs modernes reposent sur ce que l’on appelle l’hypothèse générationnelle (generational hypothesis). L’hypothèse est simple mais empiriquement solide : la majorité des objets meurent jeunes, tandis qu’une petite fraction seulement a une longue durée de vie.
Pour cette raison, la mémoire est généralement divisée en générations. Les objets jeunes sont collectés fréquemment au moyen de cycles légers, tandis que les objets de longue durée sont promus dans des zones plus anciennes, analysées moins souvent mais de manière plus coûteuse. En conséquence, tous les cycles de garbage collection ne se valent pas. Certains sont rapides et presque imperceptibles ; d’autres sont plus rares mais nettement visibles.
Du point de vue du développeur, cela explique pourquoi certains schémas d’allocation semblent peu coûteux, tandis que d’autres provoquent soudainement des retards sensibles. Ce comportement n’est pas aléatoire, mais découle de l’adéquation — ou de l’inadéquation — entre les durées de vie réelles des objets et les hypothèses du collecteur.
Dans le même temps, les développeurs font souvent une hypothèse erronée cruciale. Il est tentant de croire que le garbage collector comprend la signification du code ou l’intention du développeur. En réalité, il ne comprend ni la logique métier, ni la sémantique, ni le moment où quelque chose n’est plus « conceptuellement » nécessaire.
Le garbage collector comprend les références. Si un objet est atteignable, il est considéré comme vivant. S’il ne l’est pas, il est considéré comme un déchet. C’est l’intégralité du modèle, sans aucune dimension mystique.

Cela conduit à des situations qui surprennent fréquemment les développeurs. Une seule référence involontaire peut maintenir en vie tout un graphe d’objets. Dans les langages à garbage collection, une fuite mémoire ne signifie généralement pas que la mémoire n’est jamais libérée, mais que des objets restent atteignables plus longtemps que prévu. Une fois ce mécanisme compris, de nombreux problèmes auparavant mystérieux apparaissent comme des conséquences logiques.
Un même problème, des langages différents, des responsabilités différentes
Bien que le principe fondamental de la garbage collection soit cohérent, les langages de programmation répartissent la responsabilité de manière très différente.
Java et Go sont conçus dès l’origine autour de la garbage collection. Les développeurs peuvent allouer des objets librement, et le runtime se charge de la libération. Cela conduit souvent à un code plus lisible et à un développement plus rapide, mais cela déplace également une partie du contrôle des performances hors des mains du développeur. Le collecteur prend ses décisions sur la base d’heuristiques globales plutôt que dans le contexte de requêtes individuelles. Il en résulte des pauses, des pics de mémoire et, parfois, un comportement difficile à prévoir.
Ces pauses sont communément appelées événements stop-the-world. Lors de tels événements, l’exécution normale du programme est temporairement interrompue afin que le garbage collector puisse opérer en toute sécurité. Tous les threads applicatifs sont mis en pause, la mémoire est analysée, et l’exécution ne reprend qu’ensuite. La durée de ces pauses peut aller de presque imperceptible à plusieurs millisecondes, voire davantage, selon la charge et la stratégie de GC. Dans l’écosystème JVM, une part importante de l’optimisation des performances consiste précisément à réduire ces phases stop-the-world ou à les éloigner des chemins critiques en termes de latence.

Il ne s’agit pas d’une condition exceptionnelle ni d’un état d’erreur, mais d’un élément intentionnel du modèle de garbage collection. Une fois ce fait compris, les pics de latence cessent d’être mystérieux et apparaissent comme les conséquences de choix de conception spécifiques.
En JavaScript, la garbage collection est omniprésente mais facilement ignorée. TypeScript renforce encore cette illusion. Bien que TypeScript améliore l’expérience développeur et la sûreté de typage, il ne modifie en rien le runtime. La gestion de la mémoire se comporte exactement comme en JavaScript. TypeScript change la manière de penser des développeurs, pas la manière dont les programmes s’exécutent, et oublier cela conduit souvent à un faux sentiment de contrôle.
Python et PHP représentent des modèles hybrides, combinant le comptage de références et la garbage collection. Une partie de la mémoire est libérée immédiatement, tandis qu’une autre ne l’est que lors des cycles de GC. Cela donne l’impression d’une plus grande déterminisme, mais en réalité le comportement est plus complexe. Les différents environnements d’exécution se comportent différemment, et les hypothèses concernant le moment de la libération de la mémoire s’avèrent fréquemment incorrectes.
C++ et Rust offrent un contraste éclairant. En C++, le développeur assume l’entière responsabilité de la gestion mémoire, ce qui permet un comportement prévisible au prix d’erreurs potentielles. Rust pousse cette logique plus loin en transférant la responsabilité vers le système de types et les vérifications à la compilation. La notion de propriété (ownership) et les durées de vie (lifetimes) obligent les développeurs à raisonner explicitement sur les mêmes questions que les garbage collectors traitent automatiquement dans d’autres langages. L’absence de garbage collector ne rend pas un langage obsolète; elle rend la responsabilité explicite.
Pourquoi comprendre la garbage collection est essentiel
Même sans optimiser de code bas niveau ni construire de systèmes temps réel, la garbage collection influence directement le travail quotidien. Elle affecte les temps de réponse, la consommation mémoire et le comportement des systèmes sous charge. De nombreux problèmes en production qui semblent énigmatiques sont en réalité des conséquences directes du comportement du garbage collector.
Lorsque les développeurs comprennent la garbage collection, leur manière d’aborder les problèmes change. Le débogage passe des symptômes aux causes profondes. Les décisions architecturales deviennent plus éclairées, et les problèmes de performance s’inscrivent dans un contexte plus large.
Lorsque l’on considère conjointement les pauses stop-the-world et le modèle générationnel, une image cohérente émerge expliquant pourquoi les garbage collectors se comportent comme ils le font. Le GC n’est pas arbitraire ; il optimise en fonction d’une réalité statistique. Les problèmes apparaissent lorsque les durées de vie réelles des objets d’une application s’écartent fortement des hypothèses du runtime.
En ce sens, le garbage collector agit comme un miroir. Il ne crée pas de problèmes à partir de rien; il les révèle.
Conclusion
Le garbage collector n’est pas un ennemi, mais il n’est pas non plus un mécanisme magique. C’est un choix architectural qui déplace la prise de décision du développeur vers le système d’exécution. Une fois ce déplacement compris, de nombreuses questions concernant le comportement des programmes trouvent des réponses claires.
La garbage collection ne libère pas le développeur de la gestion de la mémoire. Elle modifie simplement l’endroit et le moment où ces décisions sont prises. Si ce déplacement n’est pas compris, la nature réelle du logiciel reste partiellement obscure. Lorsqu’il l’est, le comportement des systèmes complexes apparaît soudain beaucoup plus cohérent — et nettement moins mystérieux.